Development
Machine Learning in Production
Despite the demonstrated power of machine learning, over the last few years, the real challenge in ML that has emerged is around how to productionize it successfully.
Author
David Sklenar, Senior Developer
Photography
Simone Hutsch
As you’re probably overly aware of by this point, the mid-to-late-2010s ushered in an era of amazing promise around Machine Learning (ML), building unending hype that seemed to permeate into every industry. Words like “super-human performance” and discussions around automation replacing workers quickly cropped up, as ML models finally provided a robust tool to interpret and predict the vast troves of data we generate with our digital lives.
Combined with cheaper, faster hardware, part of the reason there was so much excitement was the arrival of open datasets that enabled ML researchers and practitioners to test out new algorithms. Take, for example, the ImageNet dataset, a set of millions of labeled images with a thousand classes, created by Fei-Fei Li. Released in 2009, it enabled Microsoft researchers to surpass human-level image recognition for the first time in 2015. ML research has proven a remarkable tool to model all kinds of tasks; including image classification, natural language processing, activity classification, product recommendation, just to name a few.
The barrier to building these models dropped significantly, as well, as cloud notebooks, such as Google Colab, and welcoming, easy-to-use ML libraries, such as Keras, opened the door for anyone to train ML models. Combined with open datasets, such as ImageNet, any software engineer new to ML could quickly build models that were mind-bogglingly (>99%) accurate.
Now, let’s say you take that amazing ML model you’ve trained and want to use it in a production environment. According to Algorithmia’s “2020 State of Enterprise Machine Learning,” companies big and small are mainly tackling problems related to: reducing costs, generating customer insights, improving customer experiences, and internal processing automation. Remember, that 99% metric is highly tuned to the dataset you trained your model on, a historical snapshot of data. Once your model is published to production, you might find that it starts outputting a different distribution than in training, or the distribution of inputs is different, meaning your user behavior has shifted. Suddenly, that 99% is meaningless. How do you know what your model doesn’t know?
If you’re relying on ML for any core business logic or sensitive tasks, it’s important to understand the ways your model can degrade, or even completely fail. Whereas a traditional app or website might error out or crash in an obvious way to the user, ML models in production have added complexity and harder-to-diagnose failures.
Despite the demonstrated power of machine learning, over the last few years, the real challenge that has emerged is around how to productionize ML successfully.

Generalization in ML
You may be wondering where the self-driving cars are. Several companies have been testing their ML technology in Phoenix, mostly because the city has a regular grid system, is sunny for around 300 days a year, and has well-marked roadways. Their machine learning algorithms might work great there, but would you step into a driverless Lyft on a rainy day in Portland, where 3% of the roads are unpaved? Probably not yet. In this case, the model and technology has not yet proven to generalize well to the true population of situations it might encounter.
Regional variations are definitely a big generalization challenge. For natural language processing (NLP) models, you need to deal with the fact that the USA can’t agree on what to call a sugary carbonated drink (soda vs. pop. vs. coke), along with thousands of more dialectic variations. These regional differences can manifest in non-language tasks as well: in a study for clinical medical imaging algorithms, 51 of 56 were trained on data from only California, Massachuttes and New York. These models should be cautiously implemented until there is evidence that they are able to work in new places.
A medical drug is a great analogy for how you should treat your ML models. Drugs are tested for a specific population, have a known risk, are prescribed by a professional who understands contraindications to its use and are audited frequently for safety. Google put out a recommended format for labeling ML models, which is a good idea even for internal ML projects. You should approach any with the same degree of caution.
Perhaps most importantly, ML practitioners must understand that the historical data they use can be full of racial and gender bias (and many forms of other discrimination), and should avoid encoding that bias into an abstract ML model, which users may blindly trust. Unfortunately, there have been numerous failures on this front, so it’s an essential factor to be considering from the beginning. And just a reminder, ML models do not establish causation between input and output.
Model Degradation
If you’ve gotten through the challenges of building a generalized model that works for everyone, the next reality you face can be a daunting one: a model’s quality starts to degrade as soon as you finish training it. This is due to two primary reasons: data drift and concept drift.
Data drift (or population shift or covariate shift) is a slow process where the underlying distribution of your data changes, meaning that your model slowly gets worse at generalizing. An example could be a change in the age demographic of your users. Although the fundamental relationship of input and out is the same, the model accuracy will slowly worsen. The good news is that since this is a slow process, it is monitorable.
Concept drift is a more drastic degradation representing a fundamental shift in the relationship between your input and output. It’s not hard to think of a recent example when the workings of the world were fundamentally upended. When the COVID pandemic led to the shutdown of countries and businesses in March 2020, Instacart's ML model for predicting inventory dropped from 91% to 63% (think toilet paper). User buying patterns totally changed, and the historical data being used was no longer relevant. Instacart adapted by shortening their training window from several weeks to ten days.
A quick note: concept drift is not always a time series issue. ML models such as Recurrent Neural Networks can account for trends and seasonal changes, like increased shopping on weekends.
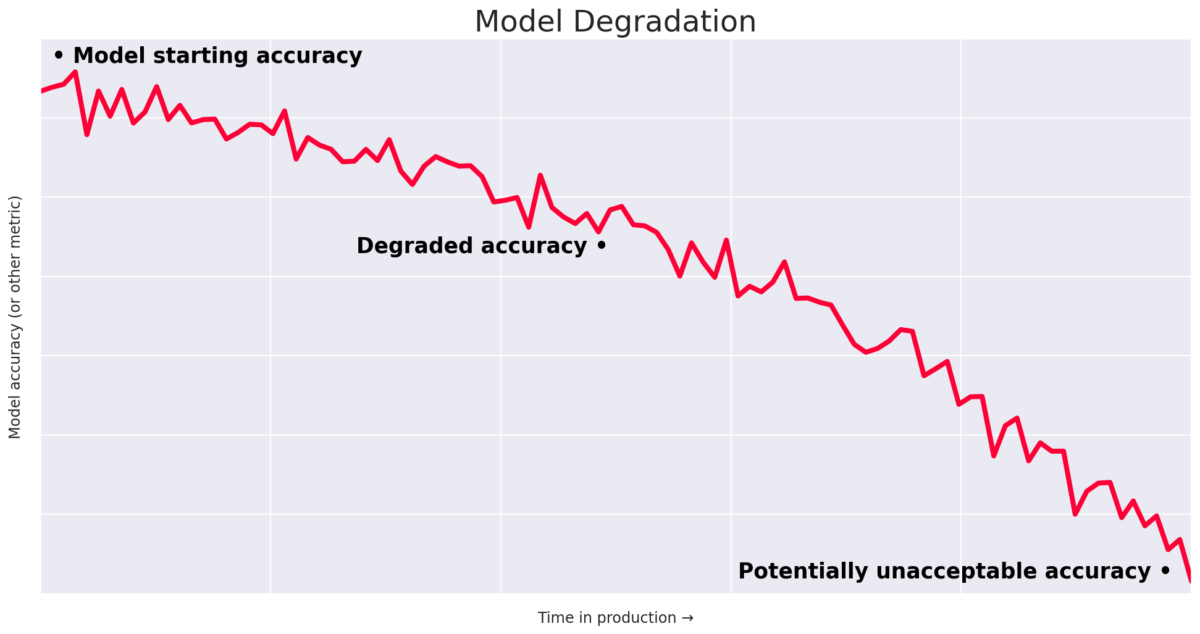
Knowing that your model can degrade and fail, how do you adapt? It’s hard to know the ground truth accuracy of your model in production because you probably can’t get your users to tell you when your model is wrong. Or, they might not even know.
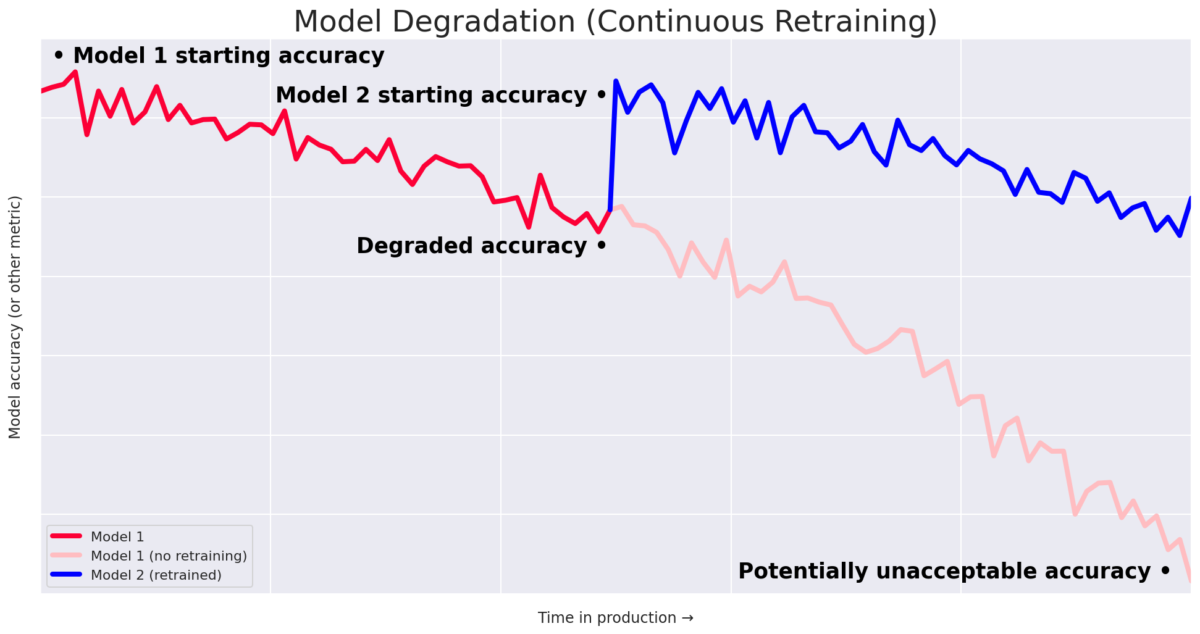
Monitoring is the most powerful tool available for detecting changes that could be signs of population drift or concept drift. Each project will be different, but it’s important to monitor your input data distribution, your output data distribution, the correlation between different features and the output, and compare those distributions to the reference distribution used in training. Your tolerance for when your reference and production distributions diverge enough will be domain-specific and likely require some iteration to hone in. Once you detect that your model is not working accurately in production, you will need to train a brand new model with better representative data.

ML Ops
All of these challenges lead to a startling fact. According to VentureBeat, 87% of ML models never make it to production.
As described, getting to the point where you can continually monitor, train, and deploy well-generalized ML models requires significant technical understanding and infrastructure. (Apparently, Google has over 500 employees working on the algorithm that recommends the next YouTube video.)
ML Ops has emerged as the hybrid discipline that encompasses all stages from data collection, to model building, to making the model available for use by the product or the consumers. Thankfully, enterprise-level tools have matured over the last several years to allow even smaller teams to utilize the powerful field of machine learning. Amazon has AWS Sagemaker, Google has TensorFlow Extended (TFX), and Microsoft has Azure Machine Learning, all of which provide a vast set of capabilities to tackle the added complexity around ML in production.
Conclusion
Hopefully, this insight didn’t leave you too daunted about training and utilizing machine learning in a production environment. As long as you’re aware of how and why your machine learning models can degrade and break, and are willing to do the work to monitor and retrain your models, production ML is feasible for teams small and large.

David Sklenar (he/him)
Senior Developer
David is a software developer with over 10 years of experience. He’s spent most of that time developing iOS apps (most recently at Nike) and has used technology to solve problems in poetry publishing, medieval architectural history, cardiac health, and digital storytelling. More recently, he’s become interested in machine learning and its applications and implementation. He most enjoys the collaborative and social nature of software development and the endless opportunities for learning.